“汤达人”给我定的毕设题目是—基于Spark的实时网页分类系统,也就是学学Spark的流处理和文本分类。大体思路我已经想好了,关于文本分类的一些东西,上学期在数据挖掘课程中已经比较熟悉了,而且Spark中也有相应的MLib支持,之后我会在数据挖掘和机器学习专题里专门讲解。所以学习Spark基本就是我的主要任务了,昨天折腾了一天终于在Windows下把Spark配置好了,今天来讲下Spark的整体背景和架构。
Spark基础
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后便成为Apache顶级项目。相比其他一些数据计算框架,Spark主打运行速度快、易用性好、通用性强和随处运行等特点。具体来说:
- 运行速度快:Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
- 易用性好:Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
- 通用性强:Spark生态圈即BDAS(伯克利数据分析栈),提供了SQL处理,流处理,机器学习和图计算相关的支持,非常方便。
- 随处运行:Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。
也就是说Spark-Core作为spark的核心库,可以用多种方式进行资源调度,读取多种持久层的数据,来完成Spark应用程序的计算。并且也被封装成了很多便捷的任务处理工具库,关系图如下(百度百科的图):
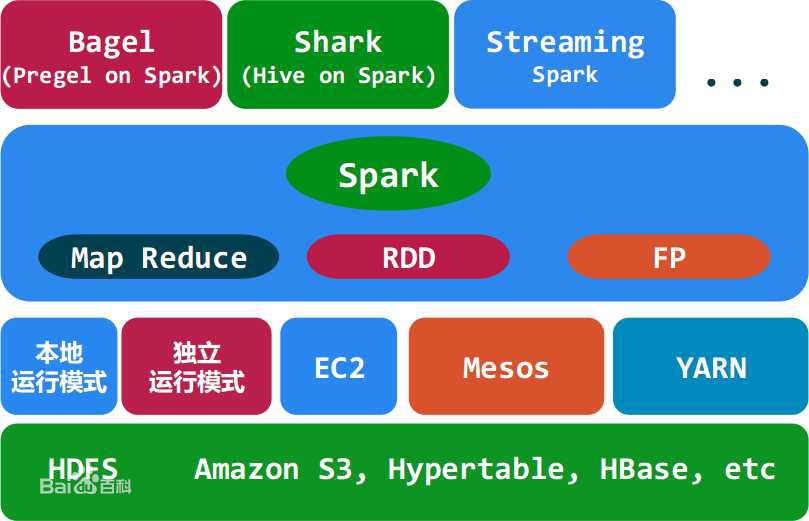
Spark是免不了被拿来和Hadoop进行对比的,事实上可以将Spark看成是对Hadoop的一种补充 ,Hadoop的两大核心分别是HDFS和MapReduce,其中:
HDFS是一种分布式文件系统,其特点是:一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
MapReduce实现的则是将任务划分交由集群处理,并对计算结果进行整合和规约。
在Hadoop Definitive Guide 这本教材中,作者将MapReduce的框架图表示如下,这里可以参考一下:
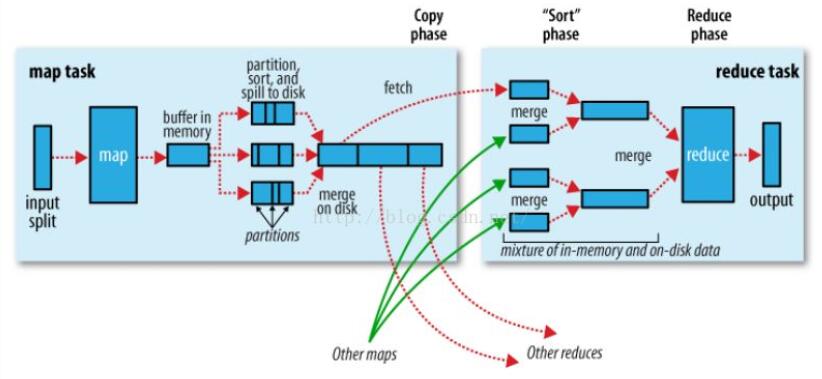
所谓的Shuffle指的就是这一系列过程。需要注意的是,关于这两个概念的任何一个都足以学习很久了,但是我们的重点是Spark,所以暂时就一笔带过了。Hadoop是一个比较低层次的框架,所以它的缺点是明显的:
- 只有Map和Reduce两个操作,表达力欠缺,不容易使用。
- 中间结果也放在HDFS文件系统中,速度慢。
- 对于迭代式数据处理性能比较差。
而Spark则是针对上述缺点做了一些跪进,它的核心是弹性分布式数据集(RDD),这个东西我觉得learning spark中讲得挺全面,这里就等于翻译一下:
RDD是一种只读的分布式对象集合,每个RDD会被划分成多个分区,在集群中的不同节点进行计算,RDD可以包含任何Java,Scala,Python对象。Spark中关于RDD的操作有两类:Transform和Action。
Transform用来定义一个新的RDD,书中的原话是construct a new RDD from a previous one。也就是说RDD是由RDD建立的,举个例子:
pythonlines = lines.filter(lambda line: "python" in line)
上一节的例子中我们建立了一个叫做lines的RDD,这里面包括指定文件里的所有行,现在我们使用filter构造一个新的RDD,它只包含含有python的行。
而Action则是返回一个RDD的计算结果,书中的原话是compute a result based on an RDD,这个结果要么返回给调用程序,要么保存在分布式文件系统里(比如HDFS)。上一节中的lines.first()就是一个典型的Action操作。
由于RDD的转换操作会生成新的RDD,新的RDD的数据依赖于原来的RDD的数据,每个RDD又包含多个分区。那么一段程序实际上就构造了一个由相互依赖的多个RDD组成的有向无环图(DAG)。Spark的Job中处理的就是这个DAG,我们可以认为Transfrom构造DAG,而Action计算DAG。现在我们再来对比下Spark和Hadoop,之所以说前者是后者的补充是因为:
| Hadoop | Spark |
|---|---|
| 只提供Map/Reduce两个操作 | Transfrom和Action都对应很多的实际操作 |
| 一个计算有多个Job完成,一个Job只有map/reduce两个阶段 | 一个计算由一个Job完成,一个Job是一个DAG的计算 |
| 中间结果存放在HDFS中 | 中间结果存放在内存中 |
| Batch式数据处理 | 交互式数据处理 |
| 迭代处理能力低 | 内存中保存数据,迭代能里高 |
Spark相关术语
这部分内容直接Copy网上博客的内容,链接在文末。首先是工作模式的相关术语,分为单机和集群,由于我的毕设肯定做的是单机应用,其他的也就用不到了:
| 运行环境 | 模式 | 描述 |
|---|---|---|
| Local | 本地模式 | 常用于本地开发测试,本地还分为local单线程和local-cluster多线程; |
| Standalone | 集群模式 | 典型的Mater/slave模式,不过也能看出Master是有单点故障的;Spark支持ZooKeeper来实现HA |
| On yarn | 集群模式 | 运行在yarn资源管理器框架之上,由yarn负责资源管理,Spark负责任务调度和计算 |
| On mesos | 集群模式 | 运行在mesos资源管理器框架之上,由mesos负责资源管理,Spark负责任务调度和计算 |
| On cloud | 集群模式 | 比如AWS的EC2,使用这个模式能很方便的访问Amazon的S3;Spark支持多种分布式存储系统:HDFS和S3 |
然后是和Spark编程相关的术语,前面其实我已经讲过几个了:
| 术语 | 描述 |
|---|---|
| Application | Spark的应用程序,包含一个Driver program和若干Executor |
| SparkContext | Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor |
| Driver Program | 运行Application的main()函数并且创建SparkContext |
| Executor | 是为Application运行在Worker node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。每个Application都会申请各自的Executor来处理任务 |
| Cluster Manager | 在集群上获取资源的外部服务(例如:Standalone、Mesos、Yarn) |
| Worker Node | 集群中任何可以运行Application代码的节点,运行一个或多个Executor进程 |
| Task | 运行在Executor上的工作单元 |
| Job | SparkContext提交的具体Action操作,常和Action对应 |
| Stage | 每个Job会被拆分很多组task,每组任务被称为Stage,也称TaskSet |
| RDD | 是Resilient distributed datasets的简称,中文为弹性分布式数据集;是Spark最核心的模块和类 |
| DAGScheduler | 根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler |
| TaskScheduler | 将Taskset提交给Worker node集群运行并返回结果 |
| Transformations | 是Spark API的一种类型,Transformation返回值还是一个RDD,所有的Transformation采用的都是懒策略,如果只是将Transformation提交是不会执行计算的 |
| Action | 是Spark API的一种类型,Action返回值不是一个RDD,而是一个scala集合;计算只有在Action被提交的时候计算才被触发。 |
Spark的生态系统
最后讲一下Spark的生态,其实我一直觉得生态这个词很夸张,其实就是各种封装而已。Spark生态圈也称为BDAS,它的目的就是提供一条龙式的服务,给你提供Spark基础接口的同时,再给你提供一系列便捷的专业数据处理接口。该生态圈已经涉及到机器学习、数据挖掘、数据库、信息检索、自然语言处理和语音识别等多个领域,十分强大。每套接口里的东西都很多,这里我肯定也只是介绍一下而已。大体来说,除了最重要的Spark-Core,比较有用的还有SparkStreaming,Spark SQL(Shark),MLBase/MLlib,SparkR和GraphX。汤达人给我的任务是实时文本分类,所以毕设里我会用到的就只有SparkStreaming和MLBase/MLlib了,而且分类算法部分是自己实现的,顶多和MLlib中的运行结果拿来对比分析一下。由于我对数据库和图计算不感兴趣,所以GraphX和Spark SQL就跳过了。SparkR就是针对R语言的一个开发包,也不打算看了。至于MLBase/MLlib,你可以把他看成是分布式的Weka。所以重点讲一下流处理这块就行了。
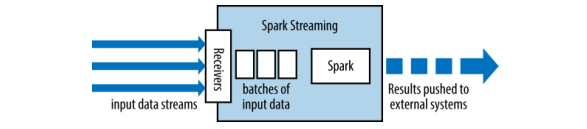
前面说了Spark相对于Hadoop的一个优点是,Hadoop只支持批处理作业,而Spark支持流式处理,它究竟是怎么实现的呢?实际上Spark Streaming用了一种比较tricky的方法,就是将流式计算分解成一系列短小的批处理作业,书中将之成为micro-batch 。这里micro-batch的划分依据是时间,为什么不采用data-size划分呢?因为我们的数据是实时获取的(边读数据边计算size并不高效,还不如直接用时钟tick),这个时间参数叫batch interval,一般选取(500ms)。这些micro-batch都会被TransForm成新的RDD并通过Action加以计算。这里书上原文讲的太好了,贴出:
Spark Streaming uses a “micro-batch” architecture, where the streaming computation is treated as a
continuous series of batch computations on small batches of data.Spark Streaming receives data from
various input sources and groups it into small batches. New batches are created at regular time
intervals. At the beginning of each time interval a new batch is created, and any data that arrives
during that interval gets added to that batch. At the end of the time interval the batch is done
growing. The size of the time intervals is determined by a parameter called the batch interval. The
batch interval is typically between 500 milliseconds and several seconds, as configured by the
application developer. Each input batch forms an RDD, and is processed using Spark jobs to create
other RDDs. The processed results can then be pushed out to external systems in batches.
大体流程如下图所示:
参考
《Learning Spark》(强烈推荐!!)