今天来学习一下python里的IO,pythonIO里的很多东西和java的还是比较对应的,很多东西看起来都很熟悉,比如:
| python | java |
|---|---|
| StringIO | Reader/Writer |
| BytesIO | InputStream/OutputStream |
| fileObject | RandomAccessFile |
| pickle | ObjectStream |
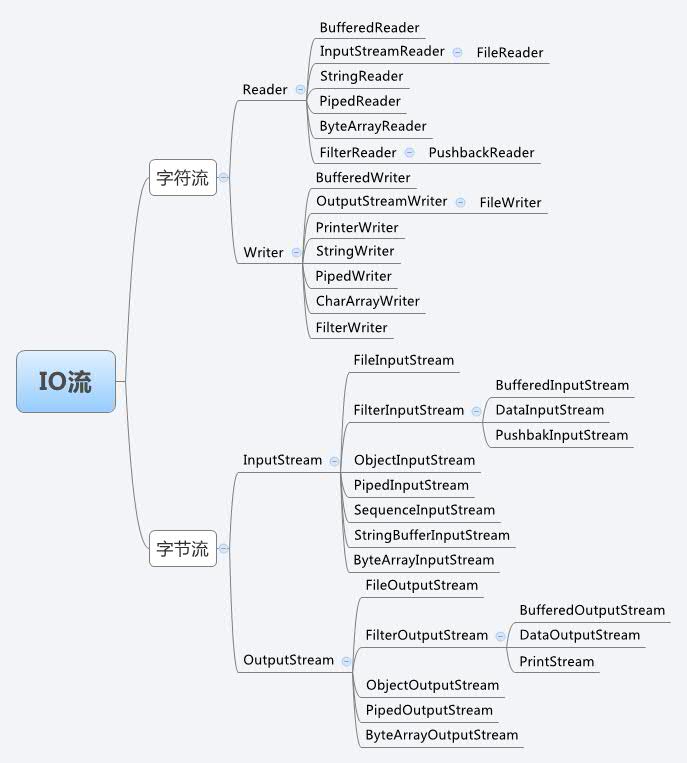
还有一些os模块里文件功能和java的File类的功能其实也是对应的,但是并不明显,所以要就是这三种,字符流,字节流,随机访问文件(来自c语言的文件访问方式,这样看来各种语言对c还是蛮尊重的)和序列化。值得注意的是python的字符流和字节流在使用的时候不需要详细规定流向,但是java必须严格指定是input还是output类型。虽然大体上有这样的对应关系,但是java在IO这块分得是要远远比python详细的,功能也比python齐全,基本上Reader和Stream下面都能再蹦出来一大堆,当时简直学得人胃疼,大概就像下图这样,大家可以感受一下:
相比IO,两者在异步IO这块就没这么多的对应了,python里面也有自己的异步IO支持aio,就像java里的nio。python里的aio和IO基本上是独立起来的,但是java里的nio常常会用到IO,比如获得个Channel呀什么的,要先用到IO(当然也可以直接去建立Channel)。而且java里的内存映射文件也是放在nio里的,需要通过Channel去获得,但是python里的内存映射文件却单独在一个叫mmap的模块里。呸~扯远了,今天的目标是学习python的IO。
python里打开文件的方式比较类似c和java的RandomAccessFile,需要指定操作类型,打开方式也很简单:
>>> f = open('E:/io/file.txt','r')
读取文件的操作也很简单:
>>> f.read()
'huper is super stupid!\n123 456\n789'
用完之后记得close:
>>> f.close()
由于open()在文件不存在的情况下抛出异常,python里不存在java里那样的“受检异常”,所以不会有人强制让你加上异常检查语句,但是这里最好还是要加上的:
try:
f = open('E:/io/file.txt', 'r')
print(f.read())
finally:
if f:
f.close()
但是这样的代码,检查语句的入侵度有点高,而且每次close也比较麻烦,所以可以这样写:
>>> with open('E:/io/file.txt','r') as f:
... print(f.read())
...
huper is super stupid!
123 456
789
read会一次性读完文件, 文件比较大的时候可以使用read(size)的方法来多次读取,或者使用readlines()的方法分行读取:
>>> with open('E:/io/file.txt','r') as f:
... for line in f.readlines():
... print(line)
...
huper is super stupid!
123 456
789
这样你会发现,readlines()方法给每行末尾自动加了一个换行,我们可以使用line。strip()来去掉末尾换行。
打开文件的时候也可以指定编码方式:
>>> f = open('E:/io/file.txt',encoding='utf-8')
>>> f.read()
'huper is super stupid!\n123 456\n789'
如果打开方式是写模式的话,还可以使用write直接来进行写操作。比较简单,这里就不练习了。接着来学习一下python里的StringIO也就是字符流:
>>> f = StringIO()
>>> f.write('123')
3
>>> f.write('123456')
6
>>> print(f.getvalue())
123123456
再来试一下BytesIO,用法基本一致 :
>>> f.write('小虎'.encode('utf-8'))
6
>>> print(f.getvalue())
b'\xe5\xb0\x8f\xe8\x99\x8e'
如果习惯了用java的话,你会觉得WTF,这是什么东西?但是python里的基础IO操作就是这么点。然后我们看下序列化,序列化的概念就不介绍了,在java里对象序列化是实现深度克隆的一个重要方法,其实现需要借助in/outoutStream和Objectin/outputStream 。python里是用到了一个叫pickle的模块(感觉给它命名”酸黄瓜”还是比较形象的),来看下用法:
>>> dict = {"huper1":100,"huper2":200,"huper3":300}
>>> import pickle
>>> pickle.dumps(dict)
b'\x80\x03}q\x00(X\x06\x00\x00\x00huper1q\x01KdX\x06\x00\x00\x00huper2q\x02K\xc8X\x06\x00\x00\x00huper3q\x03M,\x01u.'
导入“酸黄瓜”模块,然后把新建的一个字典对象倒进去准备“腌制”成美味的酸黄瓜。跟java中一样,我们可以看到序列化使用的是字节流对对象进行保存的。我们可以随时把酸黄瓜取出来:
>>> dict
{'huper1': 100, 'huper2': 200, 'huper3': 300}
>>> dict = pickle.dumps(dict)
>>> dict
b'\x80\x03}q\x00(X\x06\x00\x00\x00huper1q\x01KdX\x06\x00\x00\x00huper2q\x02K\xc8X\x06\x00\x00\x00huper3q\x03M,\x01u.'
>>> pickle.loads(dict)
{'huper1': 100, 'huper2': 200, 'huper3': 300}
loads方法必须指定一个腌制过的二进制对象,这要求我们必须把每次腌制过的东西都保存下来。我们还可以结合文件使用另一种腌制方式:
>>> f = open('E:/io/file.txt','wb')
>>> pickle.dump(dict,f)
>>> f.close()
即指定一个文件来当做腌制黄瓜的坛子,这样我们就不需要准备一个二进制对象了:
>>> f = open('E:/io/file.txt','rb')
>>> dict = pickle.load(f)
需要注意的是,pickle里取出来的东西都是原来对象的一个深拷贝。python里的json解析和pickle的模式也挺像的,都是先“倒进去”然后再“取出来”,但是json模块只能直接将dict类型的对象解析,这就是为什么python里的大多数对象都有个__dict__的域了,不得不说这些东西真的是有趣。
关于python里的文件控制,与java不同,python并没有给file相关的东西单独构建一个模块,而是选择将这些东西都放在了os模块里。因为java本身就打着平台无关的旗号,os相关的东西是坚决不让编程者碰的,而python可能希望通过os模块给编程者提供更多的发挥空间吧,这也是为什么python的多进程可以通过os模块直接使用,而java却不可以。因为可以直接使用os的调用,能组装出很多神奇的功能,这些说起来就比较长了,今天就暂时不讲了。